
When Streaming Lies
Debugging a silent failure across LangGraph, SSE, API Gateways, and Azure OpenAI

Last month I was working on a fairly standard LLM pipeline: a LangGraph based agent (with MCP tools), Azure OpenAI as the model provider (deployed on the client’s infrastructure), and a Flask API layer streaming responses back to the frontend using astream_events (v2) over SSE.
This setup had been stable. No recent code changes, no dependency upgrades, no configuration drift on our side. Then, without warning, the system started failing.
The failure surfaced as a combination of:
HTTP 400 responses from the OpenAI layer, and
a LangGraph exception:
ValueError: No generations found in stream
Initially it looked like a typical integration issue, either malformed requests, a model side error, or something breaking in the MuleSoft DataWeave layer sitting in front of the client’s OpenAI deployment. All of these were plausible, and none of them turned out to be correct.
Why This Was Non Trivial
The key constraint here was that nothing had changed in our codebase. That removes the most common debugging axis. When a previously working system fails without code changes, the only reasonable assumption is:
something outside your control has changed.
That immediately shifts the debugging strategy. Instead of tweaking code or configs, you have to isolate the system layer by layer and validate assumptions.
System Overview (Where the Assumptions Lived)
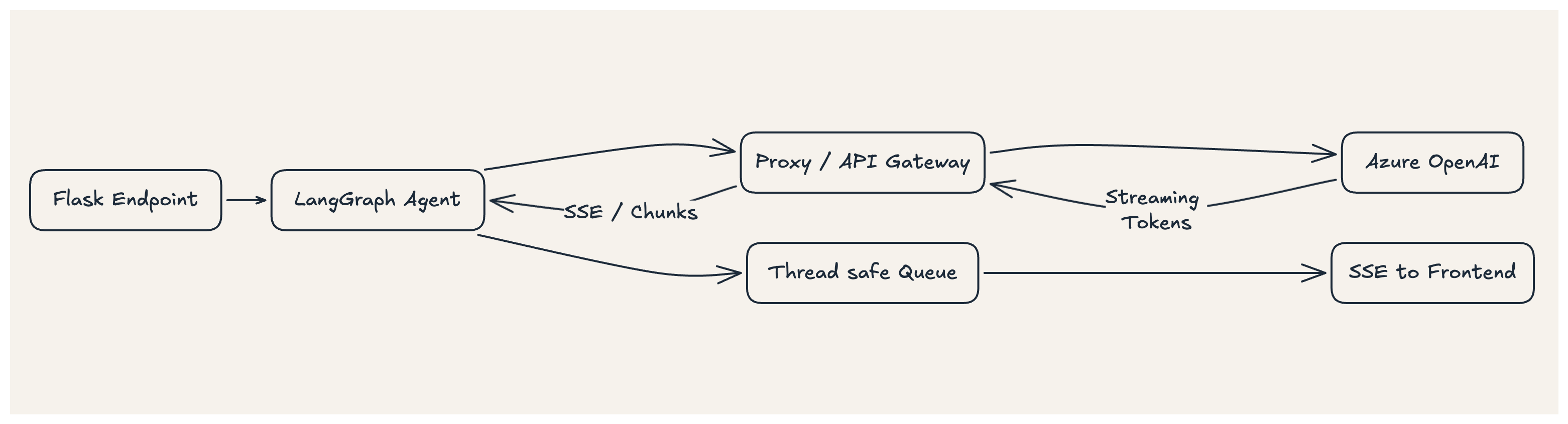
The flow looked roughly like this:
Flask endpoint receives a request
LangGraph agent executes asynchronously
The agent calls Azure OpenAI through a proxy/gateway
Responses are streamed via
astream_eventsEvents are pushed through a thread safe queue
Flask yields them as SSE to the frontend
The implicit contract in this setup is straightforward:
If
stream=True, the upstream system will deliver tokens incrementally.
Everything downstream from LangGraph, the queue, SSE depends on that being true.
Debugging by Elimination and Not Guess Work
Rather than chasing symptoms, I started validating each layer independently.
Application Layer
At first I verified that the core logic was intact:
Synchronous LLM calls worked as expected
The agent execution pipeline was correct
So this ruled out:
prompt issues
agent orchestration bugs
MCP tool integration problems
Concurrency Layer
Given Flask (WSGI) and LangGraph (async) operate on different concurrency models, I suspected event loop interference.
I refactored the execution model to:
run LangGraph in a dedicated background thread
assign a separate event loop per request
communicate via a thread safe queue
This is the standard thread + queue isolation pattern to avoid mixing blocking I/O (yield in Flask) with async execution (asyncio).
The result: no change. The failure persisted.
So I ruled out concurrency issues.
SDK / Streaming Behaviour
Next, I stripped the system down further and tested the Azure OpenAI SDK directly.
With
stream=False, responses were correctWith
stream=True, connection was established, but zero chunks were received
This is where things got interesting.
At this point, the model was reachable, the request was valid, and the connection was technically working. But no data was flowing.
That combination doesn’t point to an application bug. It points to a broken transport.
The Actual Failure: Streaming Without Data
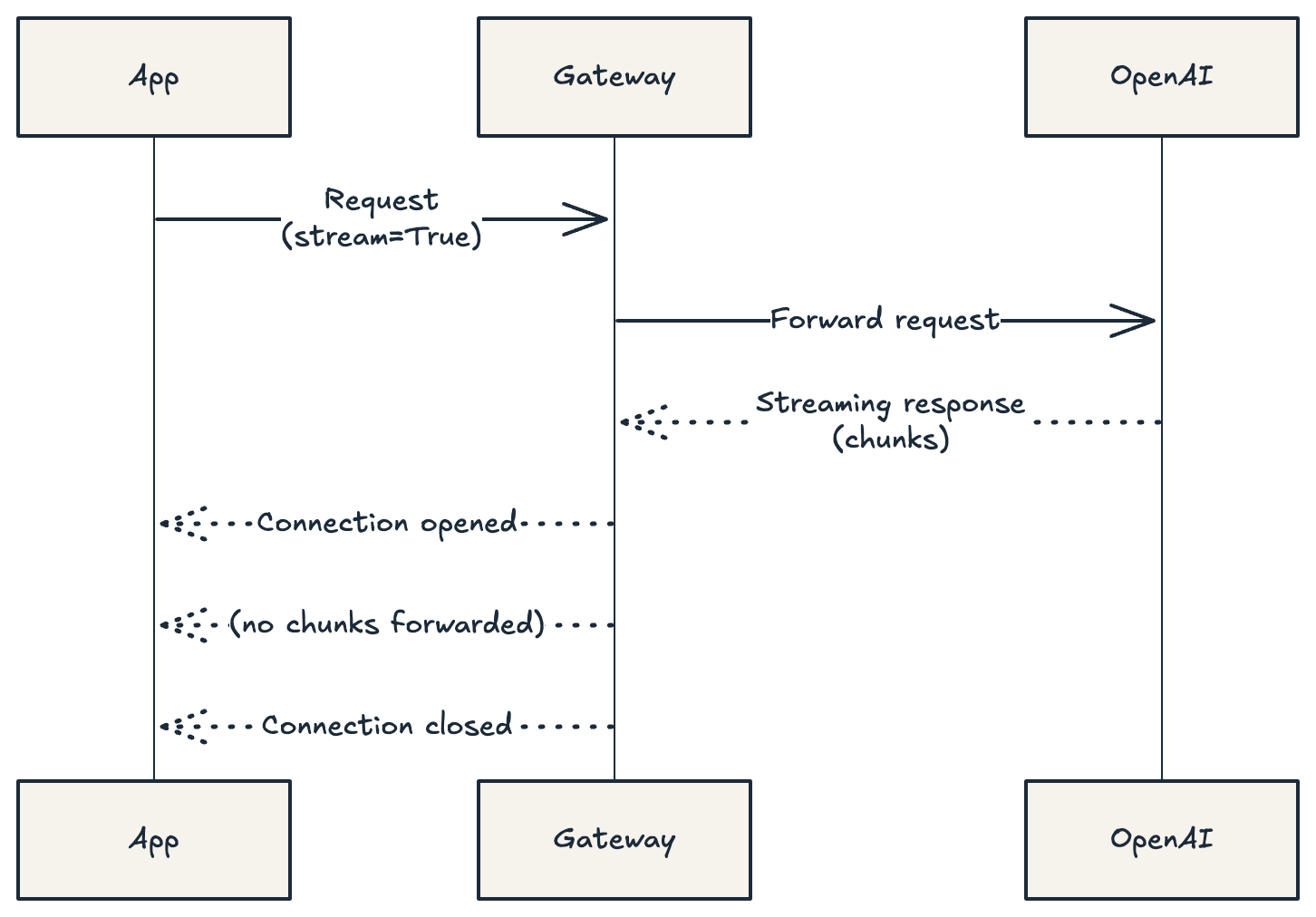
The only remaining layer was the network boundary between our service and Azure OpenAI, which was controlled by the client (API Gateway / proxy layer).
What was happening in practice:
The gateway accepted requests with
stream=TrueIt established the connection
But it did not support (or was misconfigured for) SSE / chunked transfer encoding
The connection was closed immediately without forwarding any chunks
From our system’s perspective:
the stream succeeded, but contained no data
This is a particularly dangerous failure mode because it doesn’t raise a clear infrastructure error. Everything looks connected, but the contract is already broken.
Why LangGraph Failed the Way It Did
LangGraph’s astream_events is designed around the assumption that a streaming response will produce at least one token.
When that assumption is violated:
the stream parser receives nothing
it treats this as a failure
and raises:
No generations found
So the error I saw was not the root cause. It was a downstream effect of an upstream contract violation.
What Actually Changed
Although I never got explicit confirmation, but the behaviour strongly indicates a change in the client’s gateway layer, likely around:
SSE handling
response buffering
or transfer encoding policies
The important part is not what exactly changed, but where the system became unreliable.
The Decision: Move Control Up the Stack
At this point, I had two options:
Depend on the client’s infrastructure team to fix streaming support
Remove the dependency on network level streaming entirely
The first option introduces uncertainty and external dependency. The second gives control.
I chose the second.
From Token Streaming to State Streaming
Instead of relying on token level streaming from the model, two changes were made:
Disabled streaming at the LLM layer (
streaming=False)Switched LangGraph from event streaming to state updates (
stream_mode="updates")
This effectively converts the model interaction into a standard synchronous request, while still allowing us to stream meaningful progress back to the frontend.
The system now works like this:
The model returns a fully buffered response
LangGraph emits intermediate state transitions
These updates are pushed through the queue
Flask streams them to the frontend via SSE
So the user still experiences a responsive interface, but the streaming is now:
controlled by the application, not the network
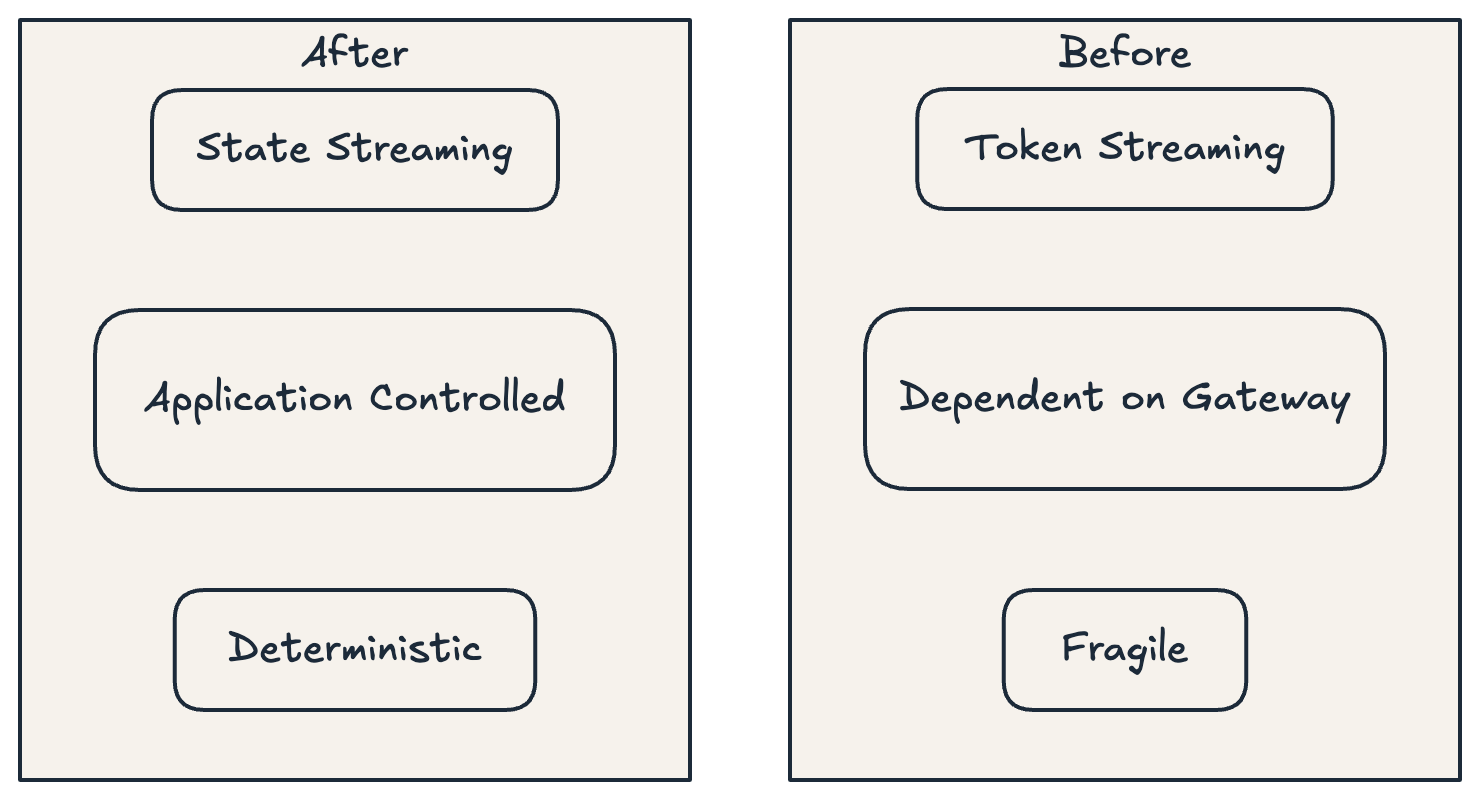
What This Changes Architecturally
Previously, streaming depended on:
correct behaviour from the gateway
proper handling of chunked responses
uninterrupted token flow
Now, streaming depends only on:
the application logic
the queue
the SSE layer
And effectively moved streaming from:
a transport layer concern to an application layer concern
Trade offs
This is not a free win.
I gave up:
token level granularity
true real time generation
And accepted:
slightly higher latency (waiting for full response)
higher memory usage (buffering responses)
In return, gained:
determinism
reliability across environments
significantly easier debugging
This is a deliberate trade.
Takeaways
There are a few lessons here that generalize beyond this specific stack:
Streaming is not just a feature, it is a multilayer contract. If any layer violates it, the failure propagates unpredictably.
Enterprise gateways are often not transparent. Even when they support streaming, they may buffer or terminate connections silently.
A stream that yields zero chunks should be treated as a transport failure, not a valid response.
When you don’t control the infrastructure, pushing critical behaviour (like streaming) into the network layer is risky.
The broader takeaway is simple:
If you don’t control the network, you don’t control streaming.
Closing Thought
What initially looked like a model or framework issue turned out to be a failure at the system boundary. The resolution wasn’t deeper debugging, it was deciding where control should live in the architecture.
Once that decision was made, the fix became straightforward.
If you have come this far, would love to hear your thoughts, ideas or suggestions on this article.
